Explainability
Explainability describes the "thinking" behind a model’s completions so that it can be transparently comprehended by humans.
What is explainability?
Explainability is the concept of describing the reasoning behind a model’s decisions or predictions so that it can be understood by humans. The goal of explainability is to make the model’s decision-making processes transparent so that users can comprehend why a specific completion was generated.
Explainability is crucial in high-stakes domains -- such as healthcare and finance -- where the model's decisions can have a significant impact on people.
Our explainability method
The attention manipulation article describes how you can use AtMan to steer the attention of your models by suppressing or amplifying parts of the input sequences.
Aleph Alpha’s explainability method uses AtMan to suppress individual parts of a prompt to determine how each part would change the probabilities of the generated completion relative to each other.
The explainability method can be applied to both text and multimodal input.
Example: Explainability on text
In this example, we investigate which part of a prompt influences the completion the most.
Consider the following prompt annotated with the changes in the log-probs of the distribution if we suppress the respective word:

The word "French" contributed to the completion "cheese" the most. Now we adjust the prompt to see how this can change:
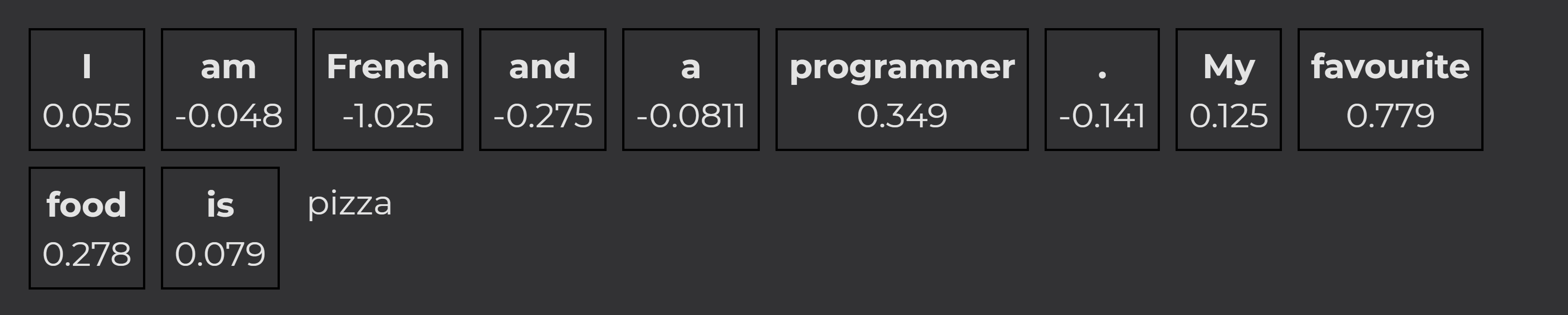
This new completion and the respective scores are interesting for several reasons. First, we get a different completion even though we only changed the prompt marginally. The words "programmer", "favourite", and "food" contributed positively to the completion. The combination of these words led to the completion "pizza".
At the same time, the probabilities show that "French" has the greatest influence on the completion, just in a negative direction this time. This indicates that the word "French" made the completion "pizza" less likely.
Example: Explainability on images
In this example, we provide text and an image as input. We can see how the text and the image contributed to the completion:


The word "instrument" and the tile containing the head of the guitar contributed most to the completion.
Example: Hallucination detection
LLMs have an occasional tendency to produce completions that seem plausible, but contain made-up, irrelevant, or incorrect information. These completions are called hallucinations.
In this example, we ask a question that the model answers based on world knowledge while ignoring the context:
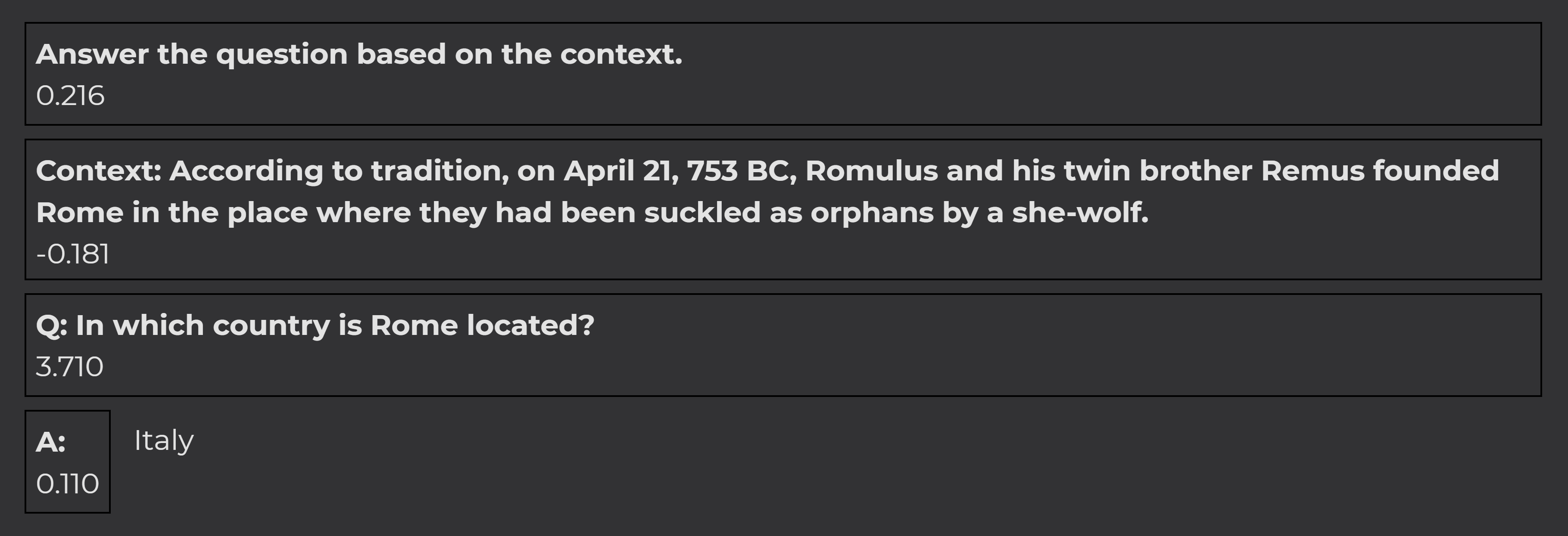
The context did not contribute to the explanation at all, indicating that the answer is a hallucination.
Now we ask a question where the answer is in the text. The contribution of the prompt is much higher, giving us a good indication of the quality of the reply:
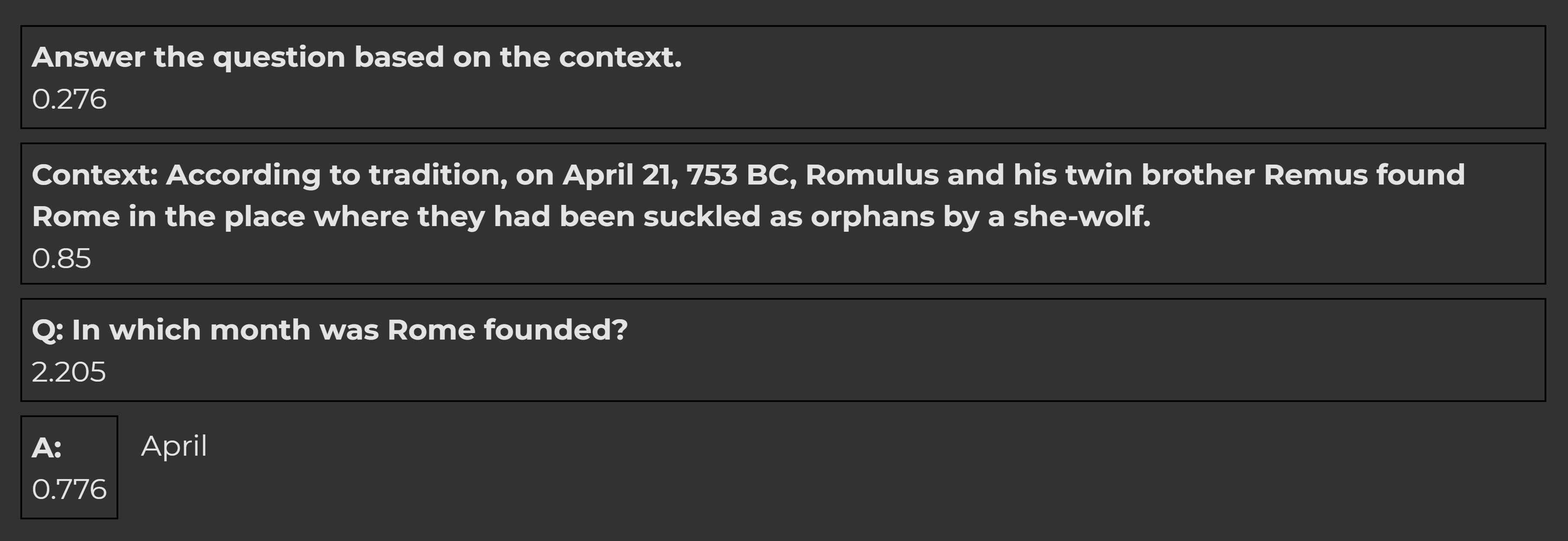
The context had a significant positive influence on the completion. Therefore, we can assume that the answer is not a hallucination and stems from the context that we provided in the prompt.