How to upload data for PhariaFinetuning
The finetuning service allows users to upload data via the API before starting their finetuning jobs.
You can upload the data through the Swagger UI. Your Swagger UI will be accessible at:
https://pharia-finetuning-api.<YOUR_CONFIGURED_URL_POSTFIX>/docs#/
where <YOUR_CONFIGURED_URL_POSTFIX> is the URL postfix configured during the installation of the Pharia-finetuning Helm chart.
Data Upload
1. Authorize
- Go to the PhariaStudio page and log in if necessary
- In the upper right corner, click on your profile
- In the popup, click on
Copy Bearer Token

Once you have the token:
- Click on the "Authorize" button in the top-right corner of the Swagger UI.
- Paste your token to authenticate.
- After authorization, you can safely close the popup window.
2. Data Format
Your dataset needs to be in a JSONL format with the following structure:
{ "messages":[ { "role":"user", "content":"user_content" }, { "role":"assistant", "content":"assistant_content" } ] }
{ "messages":[ { "role":"user", "content":"user_content2" }, { "role":"assistant", "content":"assistant_content2" } ] }
...
The dataset can also contain system messages, which is typically in the order system -> user -> assistant.
{ "messages":[ { "role":"system", "content":"system_content" }, { "role":"user", "content":"user_content" }, { "role":"assistant", "content":"assistant_content" } ] }
{ "messages":[ { "role":"user", "content":"user_content2" }, { "role":"assistant", "content":"assistant_content2" } ] }
...
Notes:
- In the latter case, the dataset is made of the first message containing
systemas role, while the remaining messages will be alternatingusertoassistantroles. - While the general structure is validated, the specific order of roles is not.
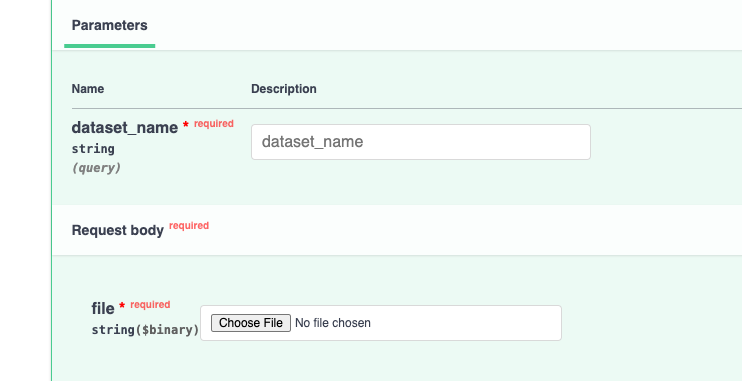
3. Uploading Your Data
To upload a dataset use the POST /api/v1/finetuning/datasets route in Swagger UI.
- Example dataset ID:
"558ef0ff-2137-4258-9e72-7caef8dfaf35"
You can select which file you want, you can also give your dataset a name using the dataset_name field.
4. Get Your Datasets
Now that you have uploaded your dataset, you can retrieve them using the GET /api/v1/finetuning/datasets route in Swagger UI.
Example:
[
{
"dataset": {
"dataset_id": "af259f8d-e83a-4b07-92a1-99ff28a36110",
"validation_dataset_id": null,
"limit_samples": null
},
"name": "test1",
"total_datapoints": 2,
"updated_at": "2025-03-05T15:56:01Z",
"created_at": "2025-03-05T15:56:01Z"
},
{
"dataset": {
"dataset_id": "4261202e-9734-4091-acbc-ac26cb10c5c0",
"validation_dataset_id": null,
"limit_samples": null
},
"name": "messy_data",
"total_datapoints": 2,
"updated_at": "2025-03-05T14:03:20Z",
"created_at": "2025-03-05T14:03:20Z"
}
]
Dataset Limitations
Sequence Length Considerations
- Maximum Sequence Length: 1600 tokens
- Combined length of user input and assistant response should not exceed 1600 tokens
- Sequences of 2048 tokens or longer will cause training failures
Resource Utilization (Testing with Aleph-Alpha/Pharia-1-LLM-7B-control-hf)
- Two worker nodes (NVIDIA A100 80GB GPU RAM and 100GB CPU RAM per node)
- 1600 token sequence consumption:
- GPU Memory: ~80GB (first node), 74GB (second node)
- CPU RAM: 65GB per node
Scaling Considerations
- Infrastructure can be scaled by adding more nodes or larger VRAM GPUs
- This allows extending the maximum supported sequence length